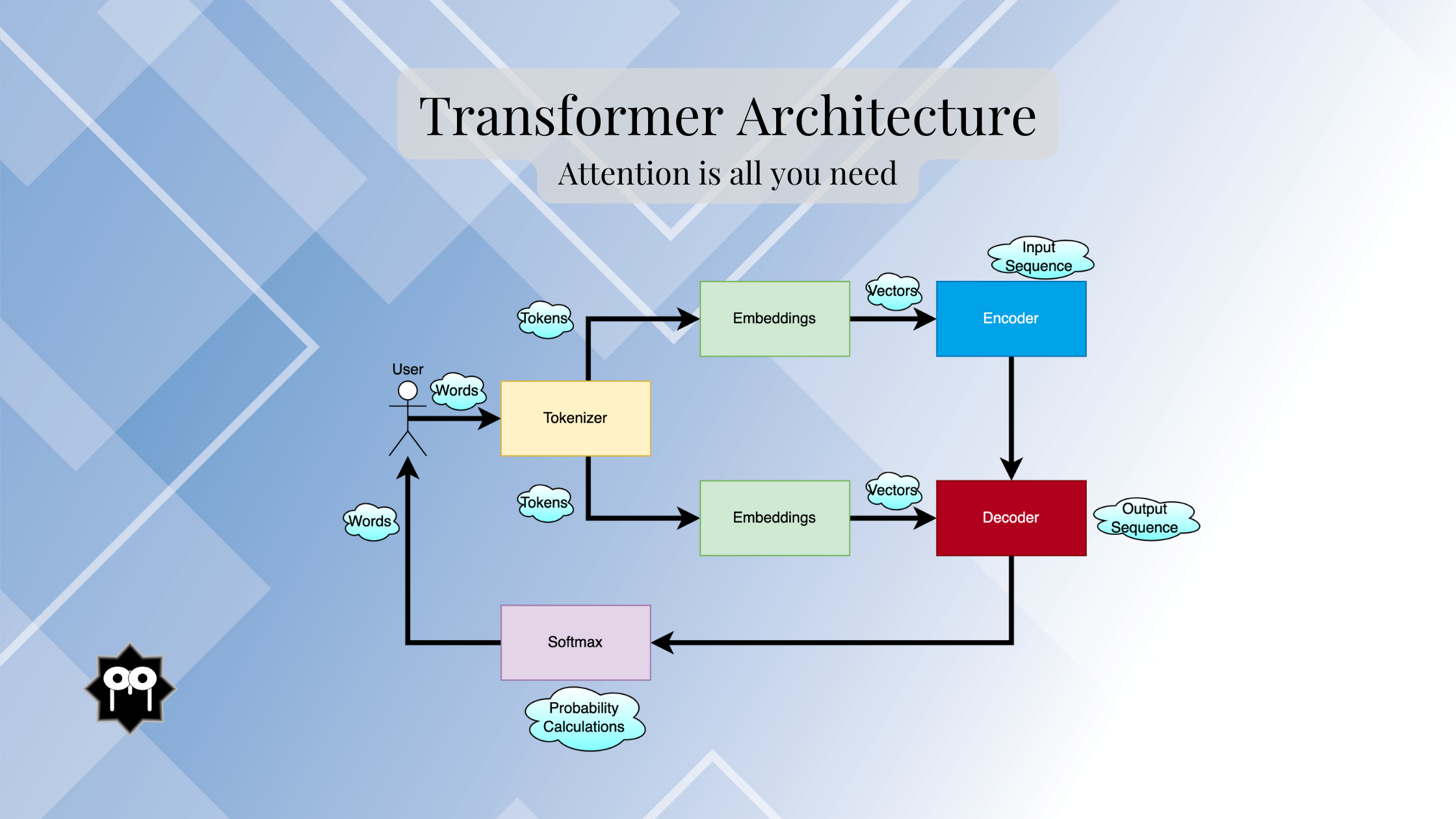
Transformer Model
Have you ever gotten frustrated with chatbots that just don’t seem to understand the full flow of conversation? Or maybe you’ve noticed machine translations that miss the mark completely. Well, there’s a reason for that – until recently, computers had a tough time understanding the deeper connections between words in a sentence. But a game-changer called the Transformer model is here!
The Transformer model is a deep learning architecture introduced in the paper “Attention is All You Need”. It revolutionized the field of natural language processing (NLP) by introducing a novel mechanism based on attention rather than recurrent or convolutional layers.
Attention mechanism allows the model to focus on important words and generate contextual meaning from them.
Text generation before transformer
In the early days of text generation, computers relied on a technique called Recurrent Neural Networks (RNNs) to churn out sentences word by word. Imagine a student answering a series of questions, only able to consider the answer they just provided. RNNs worked similarly, predicting the next word based on the few words that came before it. This approach worked well for short sentences, like composing basic greetings or short commands. However, as sentences grew longer and more complex, RNNs started to stumble.
The problem arose because RNNs relied heavily on a concept called “memory.” They needed to remember the context of earlier words in the sequence to predict the upcoming ones effectively. But with limited computational power at the time, this memory became unreliable. The context of earlier words would either fade away entirely (vanishing gradients) or become disproportionately magnified (exploding gradients), making it difficult for the RNN to accurately predict the next word and capture the overall meaning of the sentence. Furthermore, RNNs inherently struggled to grasp long-range dependencies between words spread far apart in a sentence. This meant they could miss subtle connections and nuances that are crucial for understanding the true intent of the text. As a result, RNN-based text generation often produced grammatically correct but nonsensical outputs, lacking the flow and coherence of natural language.
Transformer Architecture
The below architecture diagram is picked from the mentioned paper above.
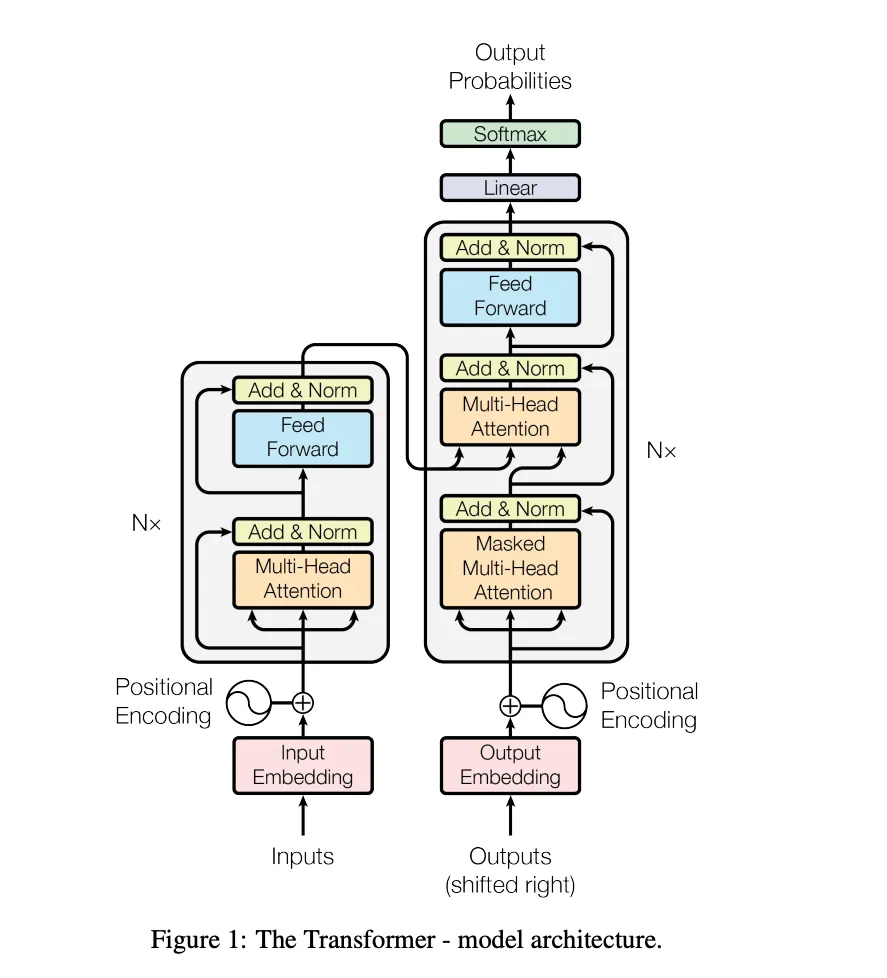
The architecture consists of the following components :
Tokenizer : Chopping up the text for the LLM
Imagine you’re giving instructions to a machine that only understands basic building blocks. To make things clear, you wouldn’t just dump the entire instruction at once, right? You’d break it down into smaller, easier-to-understand pieces. That’s exactly what a tokenizer does for a Large Language Model (LLM).
A tokenizer acts like a special tool that takes a sentence and chops it up into smaller units called tokens. These tokens can be words, punctuation marks, or even smaller pieces like letters (depending on the specific LLM and task). Just like you wouldn’t ask your machine to understand a whole sentence at once, the LLM can’t process a giant block of text either. Tokens make the information manageable for the LLM, allowing it to work more efficiently.
Here’s a deeper dive into how tokenizers function:
Vocabulary: LLMs have a defined vocabulary, like a shortlist of words they understand. The tokenizer checks each piece of text against this vocabulary and breaks it down into the corresponding tokens. Going Beyond Words: Sometimes, tokenizers don’t just split text into words. For some tasks, they might separate punctuation marks or even break words down into characters. This depends on the specific needs of the LLM and the situation. Adding Special Tokens: Think of special tokens like helper words for the LLM. The tokenizer might add these tokens to the beginning or end of a sentence to signal the start or finish, or to indicate special cases like unknown words. By breaking down text into tokens, the tokenizer plays a crucial role in preparing information for the LLM. It ensures the LLM gets bite-sized pieces it can understand and work with, paving the way for accurate and efficient language processing.
Embeddings : Turning Tokens into Meaningful Codes
Imagine you have a giant dictionary where every word has a unique code assigned to it. But this code isn’t just a random number – it captures the essence of the word, its meaning, and how it relates to other words. That’s exactly what embeddings do for tokens in the Transformer model.
Embeddings are like secret codes, but instead of words, they represent tokens generated by the tokenizer. Each token gets converted into a vector, which is basically a fancy way of saying a list of numbers. The cool part is that these numbers aren’t random – they’re carefully chosen by the Transformer model during training to reflect the token’s meaning and its connection to other tokens.
Here’s how embeddings capture meaning:
Similar Tokens, Similar Codes: In the embedding space (imagine a giant map where each point represents a token’s code), tokens with similar meanings are positioned closer together. For example, “king” and “queen” would likely have codes that are close neighbors in this space, while “king” and “key” would be much farther apart. Context is Key (For Advanced Models): In simpler models, embeddings might just represent the general meaning of a token. But advanced models take things a step further. They can generate contextual embeddings, which means the code for a token can shift slightly depending on the surrounding words. For instance, the embedding for “play” in the sentence “Let’s play outside” might be different from the embedding for “play” in the sentence “Press play on the music.” By converting tokens into embeddings, the Transformer model goes beyond just recognizing individual words. It creates a meaningful representation of language, allowing it to understand the relationships between words and generate more natural and coherent text.
The Encoder: Unveiling the Hidden Connections
Imagine you’re reading a detective story. To understand who committed the crime, you need to analyze all the clues, not just the ones that appear right next to each other. The Transformer’s encoder works in a similar way. It takes the token embeddings, those secret codes packed with meaning, and analyzes them all together to uncover the hidden connections and understand the overall context of the text.
The encoder is like a master detective board. It lays out all the embeddings (clues) and uses a special technique called self-attention to see how each piece connects to the others. Self-attention allows the encoder to focus on relevant parts of the sentence, even if they’re far apart. Here’s how it works:
Beyond Neighbors: Unlike reading words one by one, the encoder can consider every token’s embedding at the same time. This lets it capture long-range dependencies – connections between words that might be separated by many other words in the sentence. For example, the encoder can understand how the subject of a sentence relates to the verb, even if they’re far apart. Not All Clues Are Equal: The encoder doesn’t just blindly analyze every connection. It assigns a score to each relationship, indicating how important it is for understanding the meaning. This ensures the encoder focuses on the most relevant clues, just like a detective prioritizing the most critical pieces of evidence.
Encoders are typically layered, with each layer building on the work of the previous one. The first layer might identify basic connections, and subsequent layers refine these connections and uncover deeper contextual information. By meticulously examining all the embeddings and their relationships, the encoder paints a clear picture of the meaning behind the words, preparing the ground for the next stage – generating a response.
The Decoder: Weaving a Response from the Unraveled Context
The encoder, like a skilled detective, has meticulously analyzed the text and uncovered its hidden meaning. But what if that meaning just sits there, unutilized? That’s where the decoder comes in. Imagine the decoder as a creative writer who takes the detective’s findings (the encoder’s output) and uses them to craft a response, like a new sentence, translation, or summary.
Similar to the encoder, the decoder is layered. Each layer takes the output from the previous layer, which is a refined understanding of the context, and builds upon it. Here’s how the decoder works step-by-step:
Starting Point: The decoder typically begins with a special start token, signaling the beginning of the response it’s about to create. Attention to the Context: Just like the encoder, the decoder utilizes attention mechanisms. But instead of focusing on all the token embeddings at once, it pays attention to the encoder’s output and the previously generated tokens in the response (if it’s a multi-word response). This allows the decoder to consider the overall context and ensure the response aligns with the original meaning. Word by Word Creation: At each step, the decoder predicts the next token in the response. It considers the previously generated tokens, the encoder’s output (the context), and its own internal knowledge to pick the most fitting word. Building Up the Response: With each prediction, the decoder adds a new token to the response, one by one. This iterative process continues until the decoder predicts an end token, signifying the completion of the response.
The type of decoder used can vary depending on the desired outcome. For tasks like generating full sentences, a different decoder architecture might be used compared to tasks that require summaries. But ultimately, all decoders share the same core function: transforming the encoder’s contextual understanding into a meaningful response. By working together, the encoder and decoder form the heart of the Transformer model, allowing it to understand and respond to language in a way that surpasses traditional methods.
SoftMax: Picking the Perfect Word (with Probability!)
Imagine you’ve narrowed down your choices to the final few words for your response, but you’re not quite sure which one lands the perfect punch. That’s where SoftMax steps in. It acts like a probability judge, analyzing the remaining candidate tokens (words) and picking the one with the highest chance of being the most fitting choice.
SoftMax isn’t a simple on/off switch. It considers the probability of each token and assigns a value between 0 and 1. Think of it like a confidence score – a higher score indicates a greater chance of being the ideal word for the situation. The magic lies in how SoftMax treats these probabilities:
Normalization is Key: SoftMax takes all the probabilities and adjusts them proportionally, ensuring they all add up to 1. This “normalization” prevents any single token from dominating the selection process unfairly. The Soft in SoftMax: By normalizing the probabilities, SoftMax avoids picking the absolute highest value every time. This “softness” allows for some flexibility, considering not just the most likely option but also giving some weight to other possibilities with decent probabilities. So, how does SoftMax use these probabilities to pick a word? It performs a weighted random selection based on the assigned probabilities. Think of it like a lottery where each token has a number of tickets corresponding to its probability score. The higher the score, the more tickets a token has in the basket. SoftMax randomly picks a ticket, and the word on that ticket becomes the chosen token for the response.
SoftMax plays a crucial role in ensuring the Transformer model generates the most relevant and fitting words for the situation. It takes the possibilities presented by the decoder and selects the one with the highest chance of success, adding a layer of refinement and making the Transformer’s responses more natural and accurate.