
A microservice is a small, independent application that is designed to perform a specific business functionality. It is a software architectural style that structures an application as a collection of loosely coupled services, each running in its own process and communicating with each other through lightweight mechanisms, such as HTTP or messaging protocols.
Today, we are going to learn how to structure an individual microservice application, and break it down into different components. We are going to use SpringBoot as a tool to design the microservice.
In a typical API structure in Spring Boot, the responsibilities of each section are as follows:
Controller: The controller layer is responsible for handling incoming HTTP requests and returning the appropriate HTTP responses. It acts as an entry point for the API and is responsible for routing requests to the appropriate service methods. Controllers are typically annotated with
@RestController@RequestMappingService: The service layer contains the business logic of the application. It encapsulates the operations that need to be performed on the data and interacts with the repository layer to fetch or modify data. Services are typically annotated with
@ServiceRepository: The repository layer is responsible for interacting with the underlying data source, such as a database. It provides methods to perform CRUD (Create, Read, Update, Delete) operations on the data. Repositories are typically interfaces that extend the
JpaRepository
Here is a diagram that illustrates the flow of data and responsibilities between these sections:
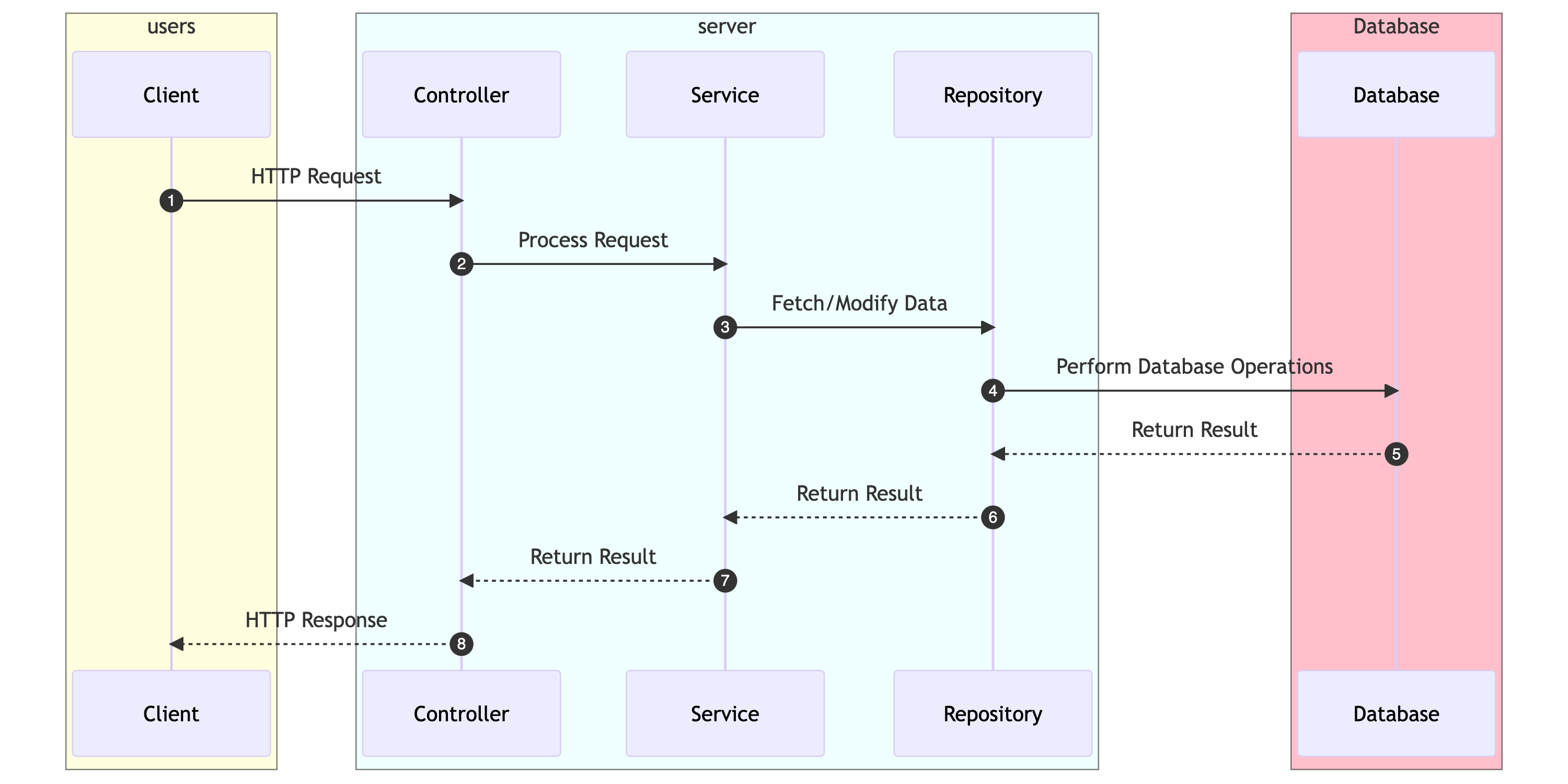
This sequence diagram shows how a typical API request is handled. The client sends an HTTP request to the controller, which then delegates the request to the service layer. The service layer interacts with the repository to fetch or modify data from the database. The result is then passed back through the layers, and the controller returns an HTTP response to the client.
It’s important to note that this is a common structure, but it can vary depending on the complexity and requirements of your application. Spring Boot provides flexibility in organizing your code and allows you to customize the structure according to your needs.
Lately, I’ve noticed a recurring anti-pattern emerging in the implementations of this particular structure during my code reviews. I’ve humorously coined this anti-pattern as “Kareena Kapoor Controllers and Fluffy Services.” While it may sound amusing, it points to a deeper issue that needs to be addressed. The term “Kareena Kapoor Controllers” refers to instances where the controller layer is kept very thin, resembling a “zero figure.” On the other hand, “Fluffy Services” alludes to service components that prioritize a love for food and an indulgence in unnecessary code, resulting in overweight and cumbersome services. These anti-patterns can hinder the overall maintainability and scalability of the codebase.

Kareena Kapoor, a renowned Bollywood actress, has been known for her passion and dedication towards maintaining a “zero figure.” Throughout her career, she has been an advocate for fitness and healthy living, inspiring many with her disciplined approach towards her physique. Kareena’s commitment to achieving and maintaining a slim figure has been evident through her strict diet plans, rigorous workout routines, and regular yoga practice.
Fluffy, whose real name is Gabriel Iglesias, is a renowned comedian celebrated for his distinctive style and larger-than-life personality. Embracing his choice to live as a larger-sized individual, Fluffy’s comedy resonates with audiences as he fearlessly incorporates his love of food and his own experiences with weight into his routines.

Example of the anti-pattern

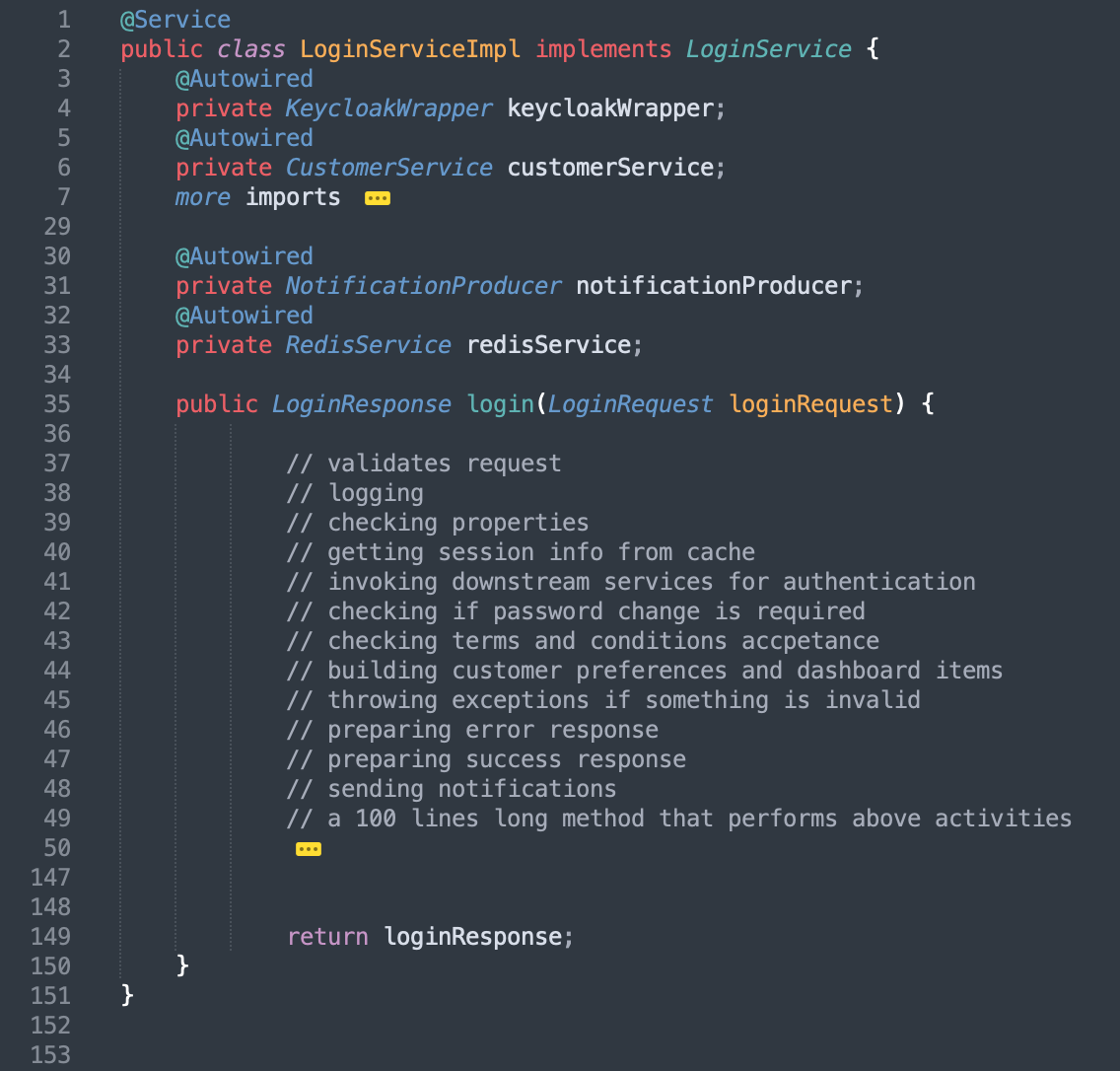
In this particular anti-pattern, developers tend to favor keeping the controllers slim, with their main responsibility being to connect with the REST API and handle incoming requests. All other tasks, including the preparation of the response, are delegated to a service layer. While this approach may seem appealing, it can have several consequences that need to be considered:
Failure to use controller as an Orchestrator (Router)
One of the important roles of the controller is to perform routing. By calling a single service method, we may fail to break down the business functionality into smaller tasks and underutilize the potential of the controller.
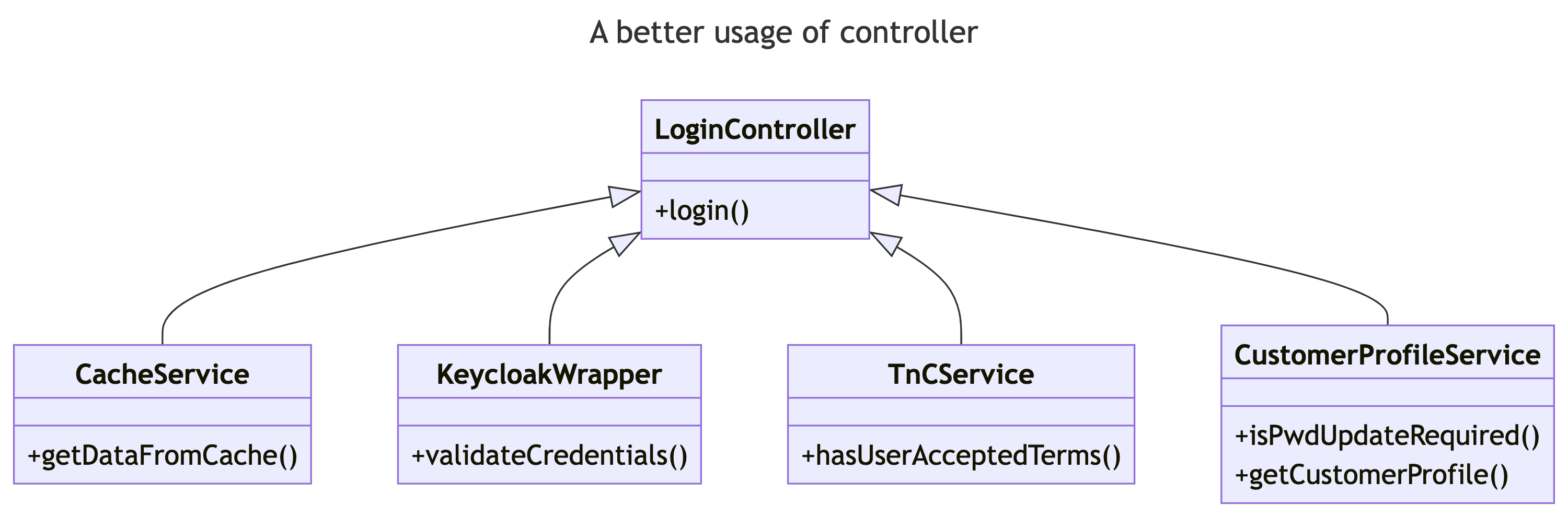
In order to address this, a change that can be made is to move away from the One-Controller-One-Service approach and instead break down the business tasks into smaller, independent chunks. Each functionality should be assigned to separate services, allowing for better modularity and maintainability.
In this revised approach, the controller’s responsibilities should include:
Validating the Request: The controller should ensure that the incoming request is valid and meets the required criteria. This involves checking the request parameters, headers, and any necessary validations to ensure the integrity of the data.
Extracting Data and Preparing Domain Objects: The controller should extract the relevant data from the request and prepare the necessary domain objects or DTOs (Data Transfer Objects) required by the services. This involves mapping the request data to the appropriate objects and ensuring that the data is in the correct format for further processing.
Invoking Independent Services: Instead of calling a single service method, the controller should invoke multiple independent services, each responsible for a specific business functionality. This allows for better separation of concerns and promotes reusability of services across different controllers or applications.
Routing Between Service Methods: The controller should handle the routing between different service methods based on the business logic and requirements. This involves invoking the appropriate service methods in the correct sequence and passing the necessary data between them.
Preparing the Response Object and Handling Success/Failure Responses: After the services have completed their tasks, the controller is responsible for preparing the response object that will be sent back to the API caller. This includes constructing the response object, setting appropriate status codes, headers, and any additional metadata. The controller should handle both successful responses and failure scenarios, such as handling exceptions, error handling, and returning appropriate error messages or status codes.
Failing Single responsibility
In addition to the previous points, there is another crucial aspect to consider when discussing the anti-pattern of Fluffy services. By following this pattern, we inadvertently place excessive pressure on a single service method.
By doing so, we violate the “S” (Single Responsibility Principle) of the SOLID principles. Combining multiple tasks within a single method not only hampers the maintainability and readability of the code, but it also significantly impacts the reusability of the service method.
When a service method takes on multiple responsibilities, it becomes tightly coupled to the specific business functionality it serves. This lack of separation of concerns limits its potential for reuse in other parts of the application or in different applications altogether. It also makes the code more fragile and difficult to modify, as any changes to one task may inadvertently impact other tasks within the same method.
To address this issue, it is essential to adhere to the principles of SOLID, particularly the Single Responsibility Principle. By breaking down the tasks within a service method into smaller, independent methods, we can achieve better modularity and improve the reusability of the code. Each method should focus on a single task, making it more maintainable, testable, and adaptable to future changes.
By ensuring that each service method has a clear and distinct responsibility, we can enhance the overall structure of the application, promote code reuse, and facilitate better collaboration among developers. Embracing the SOLID principles enables us to build scalable and maintainable software systems that can evolve with changing requirements.
Tight coupling across the layers
In the context of the mentioned anti-pattern architecture, there is a common flaw that arises when the request object is passed down to services and sometimes even to the repository. This approach increases coupling between the layers and can lead to issues in the long run.
Ideally, as we transition from one layer to another, the domain model should undergo a transformation. Each layer should have its own specific domain model that it operates with. By passing the request object directly through the layers, we violate this principle and introduce unnecessary coupling.
When the request object is propagated throughout the layers, it creates a tight coupling between the presentation layer, service layer, and data access layer. Any changes or modifications to the request object can have a cascading effect, requiring modifications in multiple layers. This not only makes the codebase more complex and error-prone but also hinders the flexibility and maintainability of the system.
To address this issue, it is recommended to introduce separate domain models for each layer. The request object received by the controller should be transformed into a domain model that is specific to the service layer. This allows each layer to have its own representation of the data, tailored to its specific needs and responsibilities. The domain model can then be further transformed into a data model specific to the repository layer for data access.
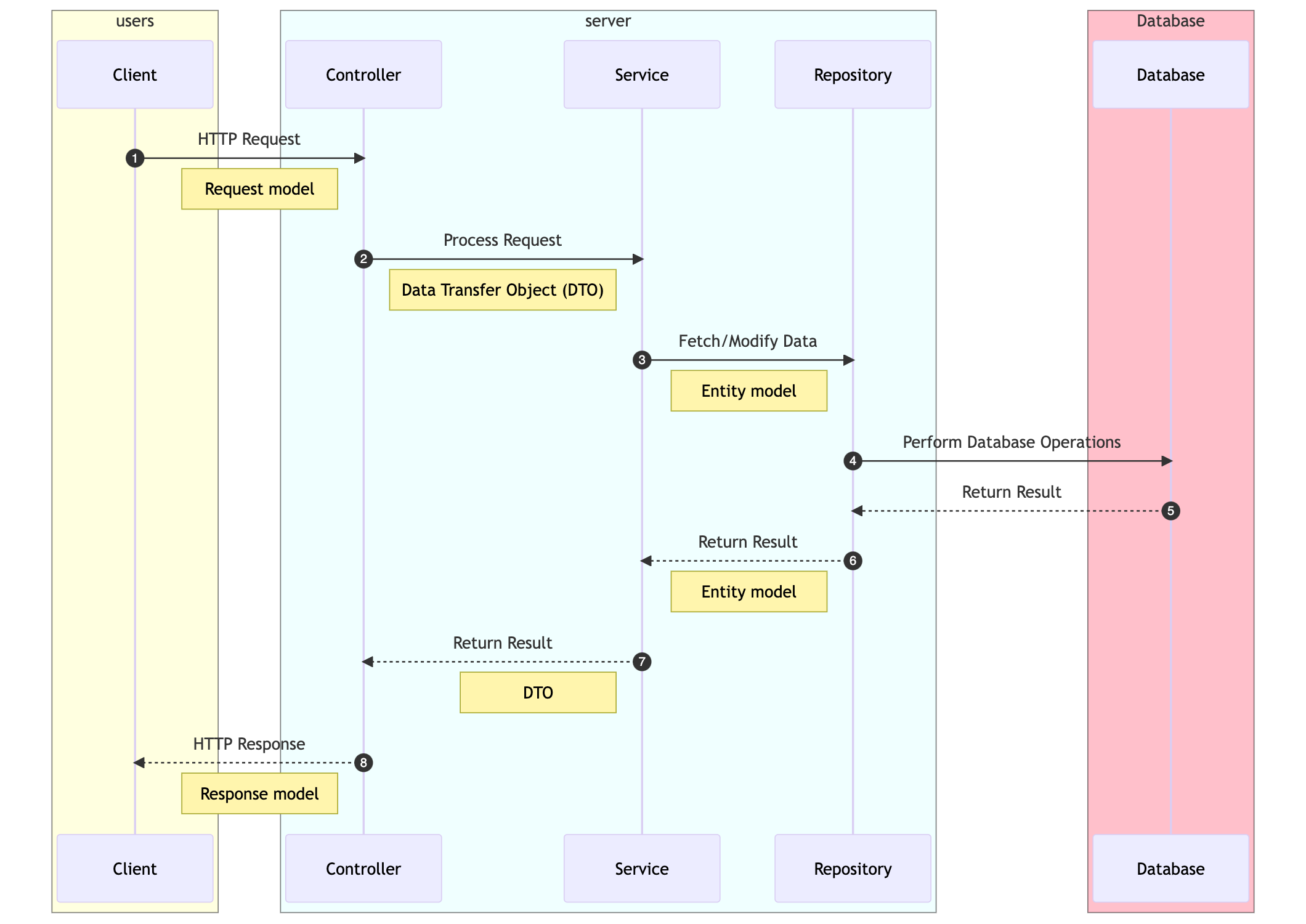
In the context of the discussed architecture, it is crucial for the controller to have awareness of the request and response structure of the API, as it serves as a common aspect for clients. However, it is equally important for the services to remain unaware of the specifics of REST requests and responses. In fact, services should not even assume that the requests are originating from a REST API. This design approach allows for future flexibility, as the same service may be invoked from a batch process or a non-REST-based application.
By decoupling the services from REST objects, we ensure that they can be reused seamlessly in different environments without the need for workarounds or “Jugad.” If services become dependent on REST objects, it would require creating fake request objects to reuse them in non-REST environments, which introduces unnecessary complexity and compromises the maintainability of the codebase.
Instead, the controller should act as a mediator between the clients and the services, translating the incoming requests into a format that the services can understand. The controller should extract the necessary data from the request and pass it to the services using domain objects or DTOs (Data Transfer Objects) that are specific to the services’ domain model. This way, the services remain agnostic to the underlying communication protocol or technology.
Reduced readability
Having large service methods significantly impacts code readability, making it difficult to understand the different tasks being performed within them. This lack of clarity increases the chances of bugs being present in the code, which may go unnoticed during code reviews.
Furthermore, maintaining and modifying long methods becomes increasingly challenging as the codebase evolves over time. Making changes to a lengthy method can be cumbersome and error-prone, as it requires a deep understanding of the entire method’s functionality and potential side effects.
By breaking down these large service methods into smaller, more focused methods, we can improve code readability and comprehension. Each method should have a clear and specific responsibility, making it easier to understand and reason about the code. This not only enhances readability but also reduces the likelihood of introducing bugs and improves the maintainability of the codebase.
Additionally, modularizing the code in this manner enables better code organization and promotes the practice of separating concerns. Each method can be individually tested, making it easier to identify and fix issues during the development process.
Reduced testability
When a method becomes overloaded with too many items, it adversely affects its testability. Having a large number of items within a method makes it challenging to isolate and test specific functionalities or scenarios effectively.
With an overly complex method, writing comprehensive unit tests becomes difficult. It becomes cumbersome to set up the necessary test data, define the expected behavior, and cover all possible code paths within the method. This lack of testability can result in inadequate test coverage, leaving potential bugs undetected.
Furthermore, maintaining and updating tests for a method with many items becomes a time-consuming task. Any modifications to the method’s functionality may require extensive modifications to the corresponding tests, increasing the risk of introducing errors or overlooking critical test scenarios.
To improve testability, it is essential to follow the principle of single responsibility and break down complex methods into smaller, more focused units. Each method should have a clear and specific purpose, making it easier to write targeted tests that cover specific functionalities.
By breaking down the code into smaller units, it becomes simpler to set up test scenarios, define expected outcomes, and ensure comprehensive test coverage. This promotes better code quality, reduces the likelihood of bugs, and enhances the overall maintainability of the codebase.
In summary, just like in our physical health, extremes of being too thin or too fat are not healthy for code either. Similarly, in code, having methods that are either too thin or too fat can lead to issues. For a healthy codebase, it is important to strive for methods that are of fair size.
Methods that are too thin, with minimal logic and functionality, can result in scattered code and reduced readability. They may also lead to an excessive number of method calls, impacting performance. On the other hand, methods that are too fat, with an overwhelming amount of code and multiple responsibilities, become difficult to understand, maintain, and test.
By aiming for methods of fair size, we achieve a balance between readability, maintainability, and testability. Fair-sized methods are focused and encapsulate a single responsibility, making them easier to comprehend and troubleshoot. They promote code reusability, as well as the separation of concerns, which enhances modularity and scalability.
Fair-sized methods also facilitate effective testing. With a clear understanding of the method’s functionality, it becomes easier to define test cases and ensure comprehensive coverage. Additionally, maintaining and modifying fair-sized methods is more manageable, as they are less prone to hidden bugs and allow for targeted modifications without affecting unrelated parts of the codebase.
In conclusion, striving for fair-sized methods contributes to a healthier codebase. It promotes readability, maintainability, and testability, enabling developers to efficiently understand, modify, and test the code. By finding the right balance, we can achieve a codebase that is not too thin or too fat, but rather healthy and robust.