In any software development project, logging plays a vital role in understanding and troubleshooting the behavior of applications. Imagine you are working on a web application that consists of multiple components, such as a frontend server, backend server, and a database. Each of these components generates logs that provide valuable insights into their operations. For example, the frontend server logs can reveal user interactions, while the backend server logs can show the processing of requests and responses. These logs act as a valuable source of information for developers and support teams to diagnose issues, track performance, and monitor the overall health of the system.
In a distributed system, like a mobile app or a microservices-based architecture, logging becomes even more critical. Consider a scenario where you have a mobile app that communicates with various microservices. Each microservice generates its own set of logs, capturing details about its specific operations. These logs help in understanding the flow of data, identifying any bottlenecks, and detecting errors or anomalies.
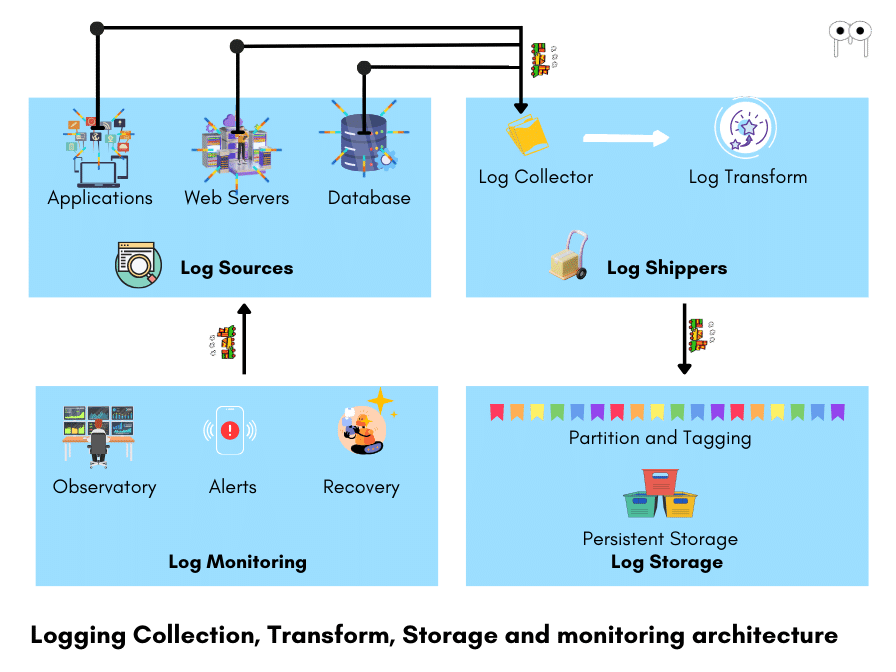
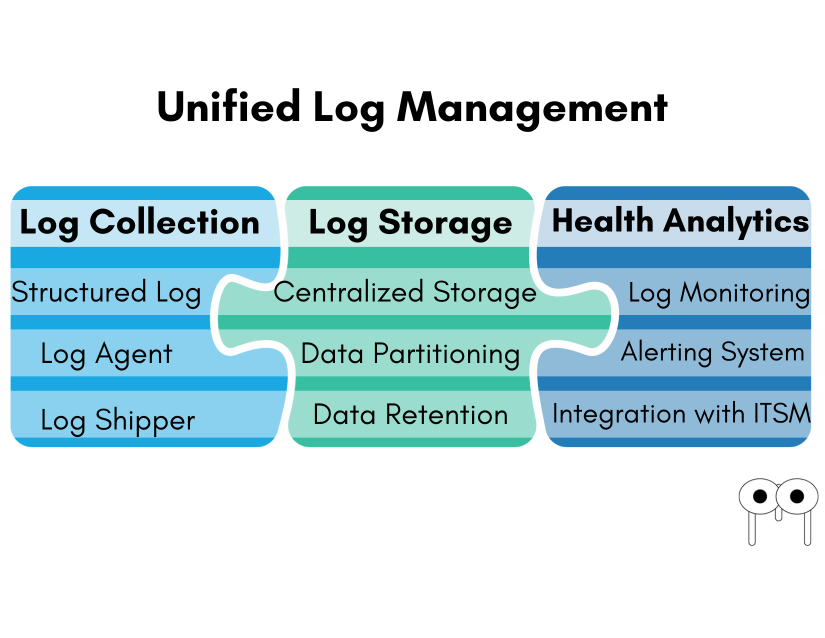
To handle the complexity of logging in distributed systems, an effective logging architecture is required.
An effective logging architecture consists of
- Log collection
- Log Storage
- Health Analytics
Log Collection
The first step in designing a logging architecture is to identify the various sources of logs within your system. Regardless of the nature of your architecture, whether it’s a monolithic application, a microservices-based system, or a combination of different technologies, each component will generate its own set of logs. These logs are crucial for understanding the behavior and performance of the system.It is the responsibility of the application developers to implement logging mechanisms that produce logs in a consistent and structured format. Structured logs are easier to analyze, search, and extract relevant information from. They typically follow a predefined format, such as key-value pairs or structured data formats like JSON or XML.
Structured Logging
Structured logging is a powerful technique that captures log messages in a structured format, such as key-value pairs or structured data formats like JSON or XML. This approach improves log readability, making it easier to extract relevant information and perform targeted searches. With structured logs, developers can quickly troubleshoot and debug issues by directly accessing specific fields or values. The structured format also enables efficient log analysis, aggregation, and visualization, empowering proactive monitoring and performance analysis. Additionally, structured logging promotes interoperability and integration with other log management systems, data pipelines, and analysis tools, facilitating centralized log management and cross-system analysis. By adopting structured logging, developers and operations teams can harness the full potential of log data to gain valuable insights into the behavior and performance of their applications.
Log Agents
A log agent is a software component responsible for capturing and structuring logs within an application or system. It is typically integrated into the codebase of the application or runs as a separate process alongside the application. The primary role of a log agent is to intercept log messages generated by the application and transform them into a structured format suitable for further processing and analysis.
Log agents play a crucial role during log collection by ensuring that logs are captured accurately and efficiently. They offer several benefits:
Log Formatting Log agents handle the formatting of log messages, ensuring they adhere to a predefined structure or format. This could involve adding timestamps, log levels, source information, or any other relevant metadata to the log entries. By enforcing a consistent format, log agents make it easier to parse and analyze logs downstream.
Log Enrichment Log agents can enrich log entries with additional contextual information. For example, they may add details about the user, session, or request being processed. This enrichment provides valuable context for log analysis and troubleshooting, enabling better insights into system behavior.
Filtering and Sampling Log agents often provide the ability to filter or sample log messages based on specific criteria. This allows for the selective collection of logs, reducing the volume of data transmitted and stored. For instance, log agents may filter out low-priority or verbose log messages to focus on critical events or errors.
Buffering and Batch Processing To optimize log collection and transmission, log agents may employ buffering techniques. They can accumulate log messages in memory or disk buffers and send them in batches to the log storage or shipping component. This reduces network overhead and improves efficiency, especially in high-throughput scenarios. Some examples of log agents include : LogBack, FluentD (Java) and Slog (Golang) etc.
Log Shippers
Log shippers are essential components in a logging architecture as they collect logs from various sources and transport them to a centralized location for further processing. They ensure efficient log collection and delivery by employing techniques such as buffering, compression, and encryption. Log shippers buffer logs to optimize transmission, reducing network overhead and enabling batched delivery. Compression reduces log size, improving transmission efficiency, while encryption safeguards sensitive log data during transit. Additionally, log shippers handle reliability and fault tolerance by retrying failed deliveries and recovering from errors. Overall, log shippers play a vital role in ensuring that logs are effectively gathered from diverse sources and reliably transported to the next stage of the logging pipeline. Some examples of log shippers include FluentBit, FluentD, LogStash etc.
Log Storage
Log storage is a critical component in a logging architecture as it handles the persistent storage of standardized logs received from log transformers. Before storage, logs are typically tagged and partitioned based on criteria such as time, source, or log level. This tagging and partitioning enable efficient retrieval and querying of logs.
Logs can be stored in various storage systems based on their retention requirements and access patterns. Common options include:
File Systems Logs can be stored as plain text files in a file system. This approach is simple and straightforward, making it easy to access and analyze logs. However, it may lack advanced querying capabilities and scalability for large log volumes.
Databases Relational or NoSQL databases can be used to store logs. Databases provide structured storage, allowing for efficient querying and indexing of logs. They offer powerful search capabilities and can handle large log volumes. However, database setups may require careful planning and maintenance to ensure performance and scalability.
Cloud-Based Storage Cloud storage services, such as Amazon S3 or Google Cloud Storage, offer scalable and durable storage options for logs. They provide high availability, redundancy, and easy integration with other cloud services. Cloud storage is suitable for distributed systems and can handle large log volumes effectively.
Specialized Log Management Platforms There are dedicated log management platforms like Elasticsearch, Splunk, or Graylog that provide advanced log storage and analysis capabilities. These platforms offer features like indexing, search, visualization, and alerting, making it easier to monitor and analyze logs in real-time.
The choice of log storage system depends on factors such as scalability, performance requirements, data retention policies, and the need for advanced querying and analysis capabilities. It is important to consider the specific needs of the logging architecture and select a storage solution that aligns with those requirements.
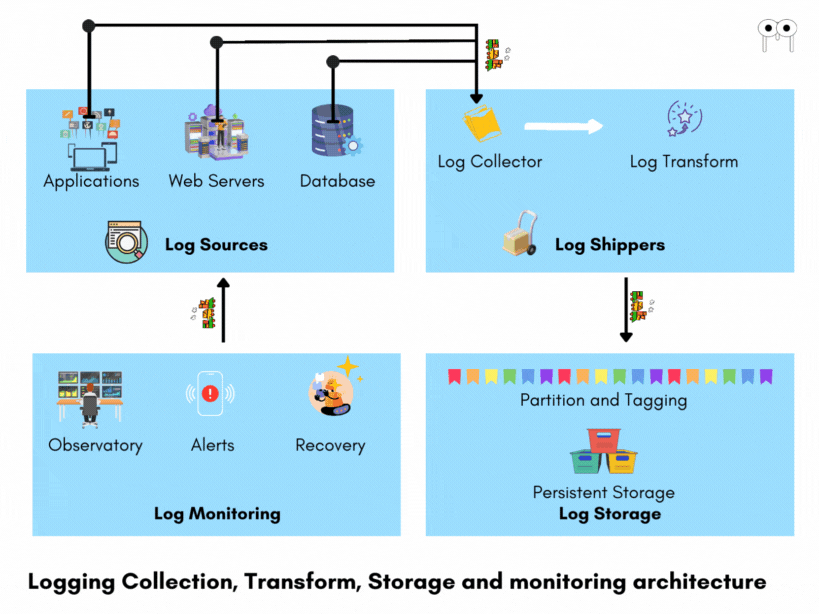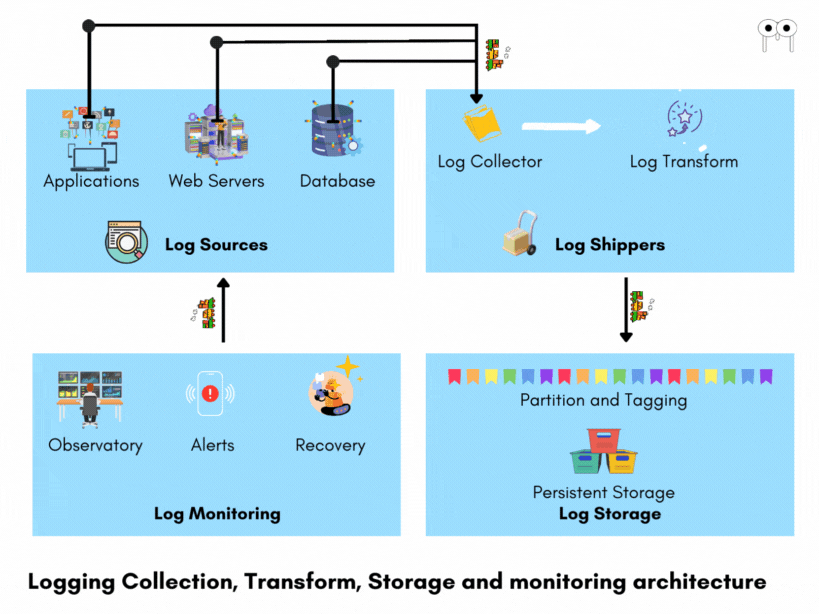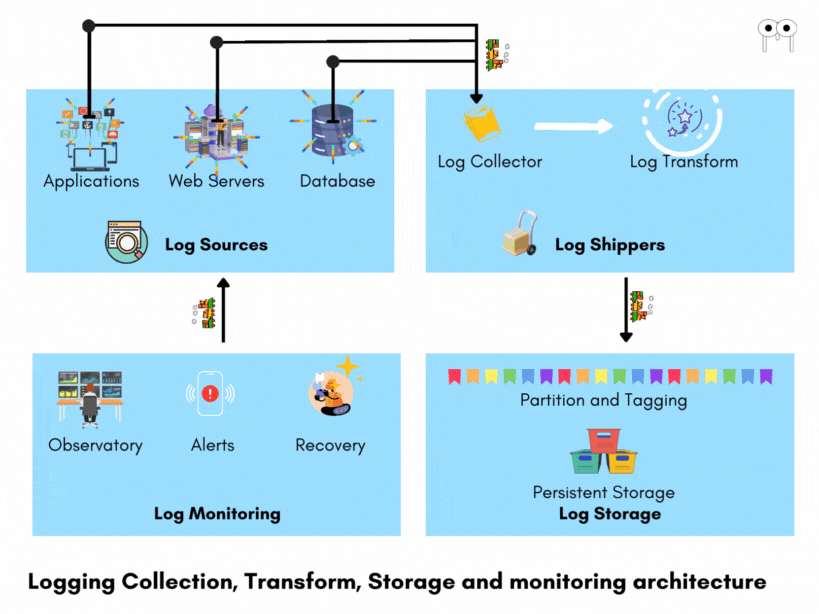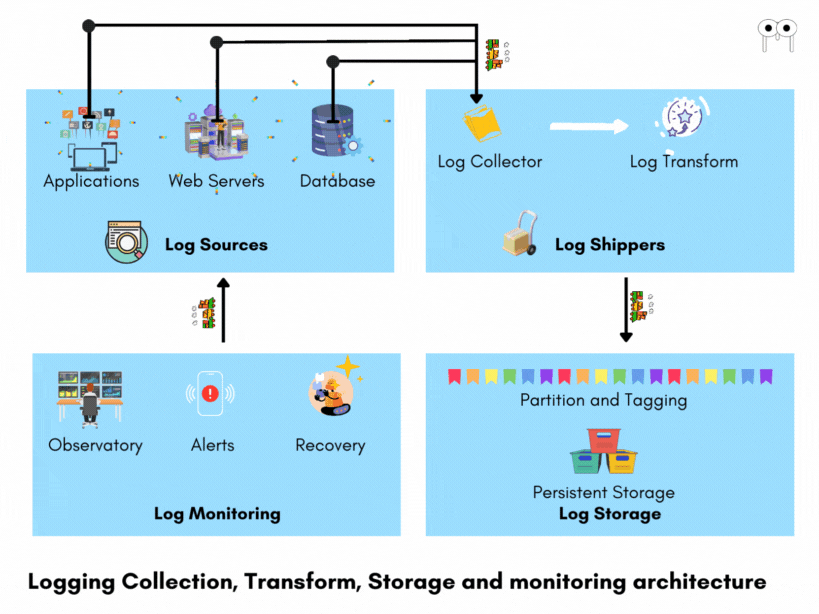
Health Analytics
Log Monitoring After logs are stored, log monitoring systems continuously observe the logs for anomalies, errors, patterns, and other critical events. These monitoring tools analyze the logs in real-time, enabling prompt detection of issues. For example, they can identify errors, exceptions, performance degradation, security threats, or any other abnormalities that may indicate problems within the system. When such issues are identified, the log monitoring systems alert the support team, providing them with the necessary information to investigate and resolve the problems.
Support and Auto Recovery Upon receiving alerts from the log monitoring systems, the support team promptly engages in investigating the logs to identify the root cause of the issues. By analyzing the log data, they can gain insights into the sequence of events leading up to the problem, helping them understand the context and potential impact. Based on their findings, the support team can take appropriate actions to resolve the issues, such as applying fixes, restarting services, or escalating to the relevant stakeholders.
In some cases, auto recovery systems can play a role in resolving problems automatically. These systems leverage the insights gained from the logs and predefined recovery mechanisms to restore the system to a healthy state without manual intervention. For example, if a critical service fails, an auto recovery system can automatically restart the service or switch to a backup instance. By leveraging the information captured in the logs and following predefined recovery procedures, auto recovery systems help minimize downtime and ensure system availability.
The combination of log monitoring, support team involvement, and auto recovery mechanisms forms a robust approach to issue resolution. Log monitoring acts as an early warning system, enabling proactive detection of problems. The support team, armed with log data, can efficiently investigate and address issues, while auto recovery systems provide automated recovery options when feasible. Together, these components contribute to maintaining system health, minimizing downtime, and ensuring a smooth user experience.
In conclusion, a well-designed logging architecture is essential for effective software development and system monitoring. By implementing the key components discussed - log collection, structured logging, log agents, log shippers, log storage, and log monitoring/support - organizations can gain valuable insights into the behavior and performance of their applications. Structured logging ensures logs are easily readable and analyzable, while log agents and shippers facilitate efficient log collection and delivery. Log storage systems store logs in a structured manner, enabling easy retrieval and analysis. Log monitoring systems continuously monitor logs for anomalies and critical events, allowing prompt detection of issues. With the support of a dedicated team and automated recovery mechanisms, organizations can investigate and resolve problems efficiently, ensuring the overall health and reliability of their systems.
By adopting a comprehensive logging architecture, organizations can leverage the power of log data to troubleshoot issues, optimize performance, and enhance the user experience. The insights gained from logs enable proactive monitoring, efficient issue resolution, and continuous improvement of software systems. With the ability to capture, analyze, and act upon log data effectively, organizations can ensure the smooth operation of their applications and provide a seamless experience to their users. Logging is not just a technical necessity but a valuable tool for enhancing the reliability, performance, and overall success of software development projects.